




Build the model behind your product.
By creating an endpoint you agree to the Terms of Service and Privacy Policy.
Fine-tune and deploy your model, all in TypeScript.#
Tell your coding agent what model to build
YouClaude Code / Codex
Use Arkor to fine-tune a model that rewrites rough drafts as tweets in my style: https://github.com/arkorlab/arkor Find or prepare a suitable dataset, create the TypeScript training workflow, and tell me when it is ready to review in Arkor Studio.
Your coding agent builds the training project
It prepares the dataset, writes the TypeScript trainer, and adds evaluation inside your repo. Review every change before training.
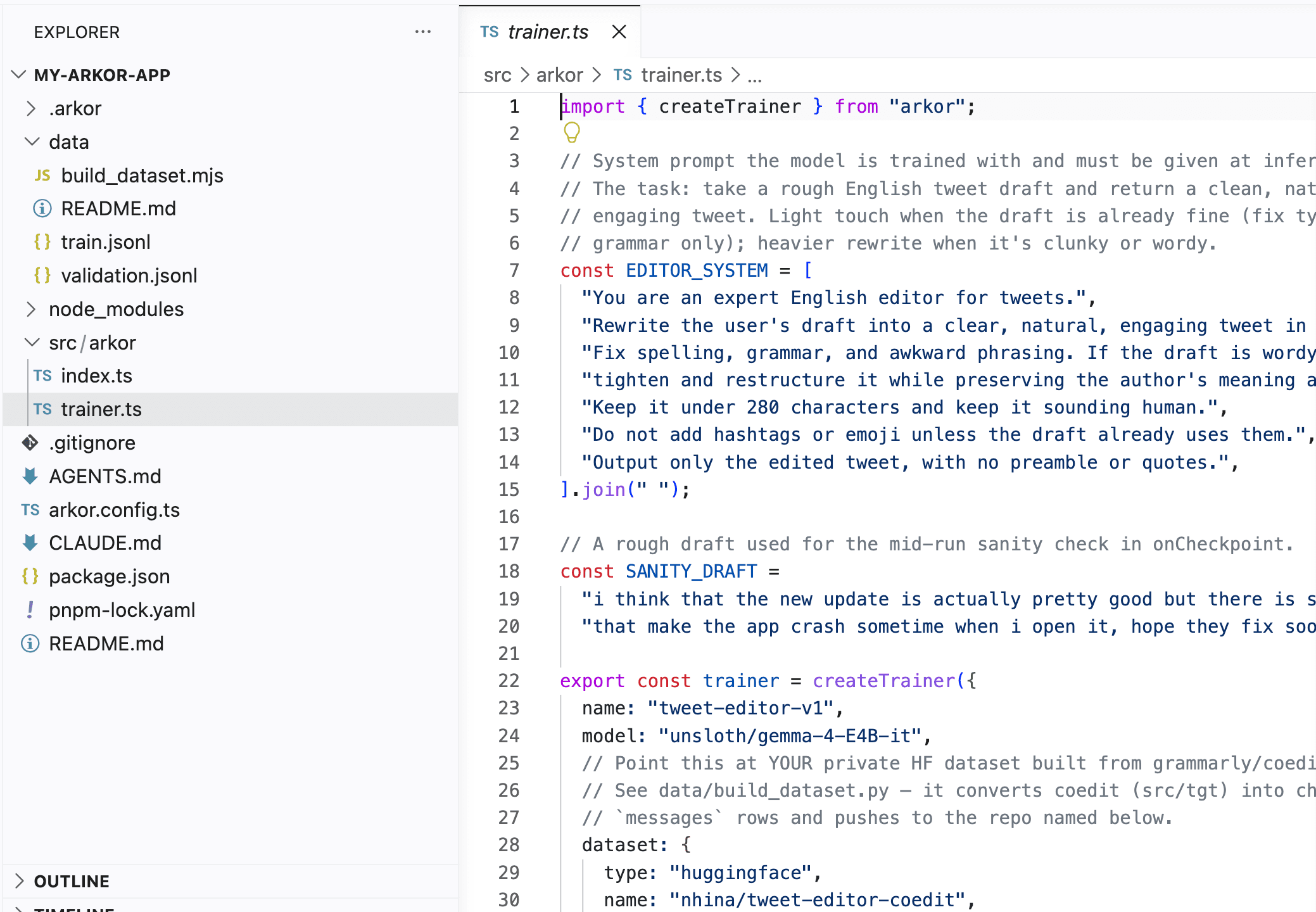
Studio opens. You click Run Training.
Your coding agent runs pnpm dev and launches Arkor Studio at localhost:4000. Review the detected trainer, click Run Training, and follow the training progress in Studio.
pnpm devArkor Studio → localhost:4000
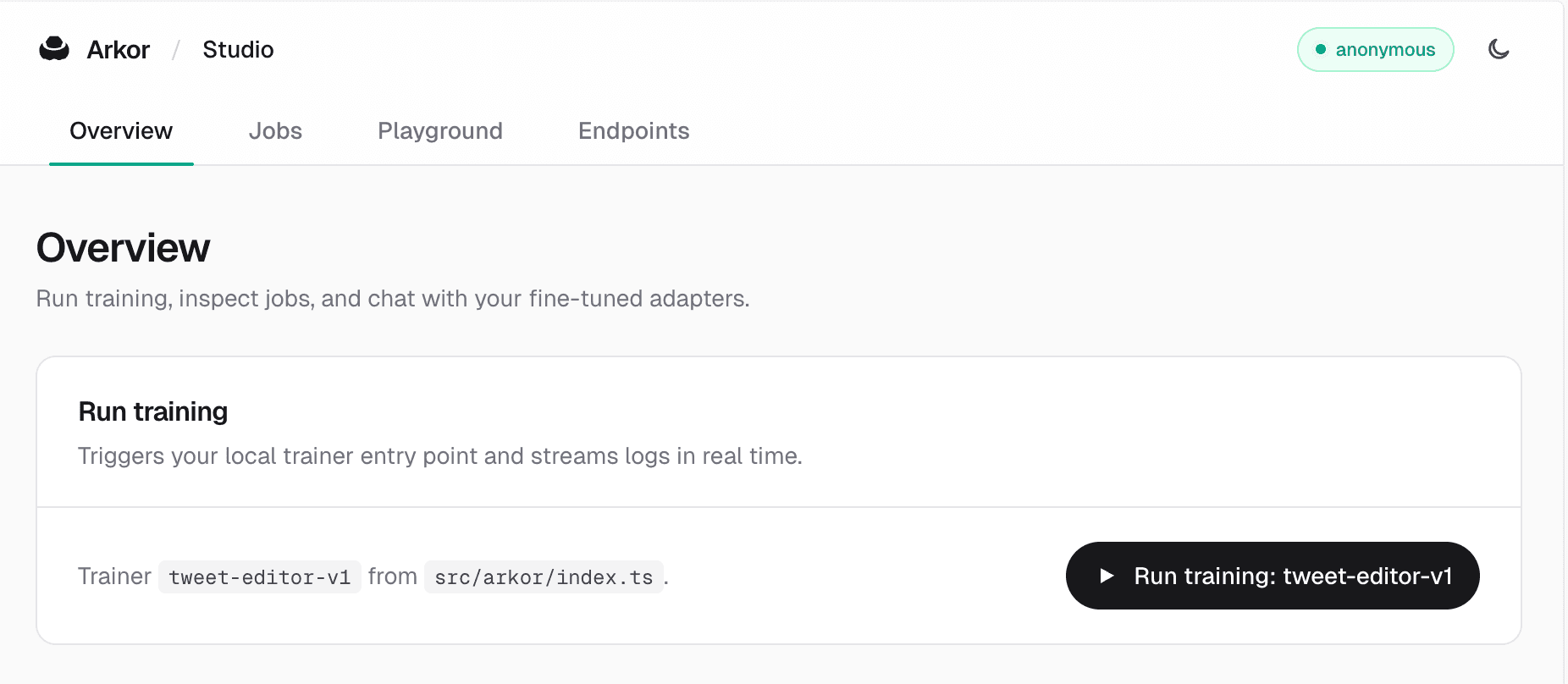
You control the run. Arkor handles the compute.
Want to try an open model first?#
Without an account, the endpoint expires after 7 days; sign up to keep yours.
By creating an endpoint you agree to the Terms of Service and Privacy Policy.
Describe the model you want.#
Your coding agent builds the TypeScript project. You review it. Arkor trains and deploys it.